Вхождение в любую науку складывается и из освоения принятых в ней методов, и из формирования характерного взгляда на вещи. Что удивительного в связи технических приемов и мировоззрения? Здесь я расскажу о некоторых простейших процедурах обработки биологических данных и одновременно — о мироконцепции, которая стоит за этими процедурами.
Три подхода к систематике
Начну издалека. В каких разделах статистики наиболее заметен вклад биологов? Если теорию вероятности развивали в основном любители азартных игр, то ключевые идеи т.н. «вариационной» статистики высказывали биологи. Фрэнсис Гальтон, Карл Пирсон, Рональд Фишер и другие учились нащупывать общие причины, скрытые покровом индивидуальных отклонений. К биологической вотчине в статистике относится и кластерный анализ, комплекс методов построения иерархических классификаций. Этот метод, название которого происходит от английского «cluster» (гроздь, пучок, группа) был описан в 1939 г. психологом Робертом Трионом. Классиками этого подхода стали американские биологи-систематики Роберт Сокэл и Питер Снит: после их «Начал численной таксономии» (1963 г.) кластерный анализ стали широко применять и в биологии, и в других науках (от астрономии до экономики, от филологии до Datamining). Что заставило биологов-систематиков вторгнуться на территорию статистики?
Ничего удивительного в том, что именно биологи развивали методы классификации, нет. Идея иерархической классификации пришла в науку через биологию. Классик систематики Карл Линней опирался на традицию, идущую еще от «отца» биологии (и целого кластера других наук) — Аристотеля.
Построение системы стало высоким искусством. Считалось, что для классифицирования какой-то группы нужно глубоко почувствовать закономерности ее разнообразия. Но одним нравятся одни классификации, другим — другие. Как обеспечить независимость разрабатываемой классификации от личности систематика? Противоречия между отношениями сходства и родства привели к появлению двух новых научных школ. Сравнение традиционной (хотя и меняющейся со временем) систематики и двух новых течений приведено в таблице.
Создатели нумерической систематики (или фенетики) Сокэл и Снит, решили, что объективным может быть лишь оценка сходства организмов. Оттачивать кластерный анализ им пришлось именно для того, чтобы изгнать из биологии субъективизм. Иное решение предложила филогенетическая систематика, развивающая подход немецкого биолога Вилли Хеннига. Классификацию, с точки зрения Хеннига, надо строить только на основании родства, вообще не учитывая сходство! Поскольку филогенетических систематиков интересовало только разветвление эволюционного древа (кладогенез), а не изменение отдельных ветвей (анагенез), их противники стали издевательски называть эту школу «кладистикой» {а мой когдатошний научный руководитель называл эту школу «яйцекладистикой»}. Сторонники Хеннига и сами приняли такую «дразнилку» для обозначения своих взглядов.
|
Авторитеты |
|
|
|
|
|
Эрнст Майр (1904-2005) |
Джордж Гейлорд Симпсон (1902-1984) |
Питер Снит (на фото) и Роберт Сокэл (р. 1926) |
Вилли Хенниг (1913-1976) |
|
|
Самоназвание |
Эволюционная систематика |
Нумерическая |
Филогенетическая систематика |
|
|
Название от противников |
«Эклектическая систематика» |
Фенетика |
Кладистика |
|
|
Классификация по… |
Сходству (в том числе — сходству по происхождению, т.е. родству) |
Только наблюдаемое сходство |
Только родство |
|
|
Основной инструмент |
Неформализованный выбор оптимального компромисса |
Кластерный анализ |
Кладистические программы |
|
|
«Объективность» |
Недостижимое качество системы |
Главный идеал |
Главный идеал |
|




Казалось бы, взгляды фенетиков и кладистиков противоположны. Но знаете, в чем они едины? Они убеждены, что их воззрения объективны. Те, кто считает, что сходство по родству является одной из компонент общего сходства и должна учитываться как его часть, постоянно обвиняются оппонентами в ненаучности их взглядов. Эти взгляды кажутся устаревшими, как и их защитник, недавно умерший в столетнем возрасте Эрнст Майр, классик систематики и теории эволюции…
Чтобы сравнить три названные школы систематики, мы попробуем классифицировать какие-то объекты с помощью «объективных» методов. Может, такая работа позволит нам прийти к каким-то существенным выводам общего характера. Что будем классифицировать? Да хоть обложки «Компьютерры»!
Для начала рассмотрим типичный (агломеративный) кластерный анализ с построением классификационного «дерева» — графа.
Первый этап кластеризации: выбор объектов для анализа
Определение исходного множества классифицируемых объектов — сложная задача. В случае серьезной работы его надо ограничить по каким-то априорным (в отношении проводимого исследования) критериям. Эти правила выбора предопределяют существенные особенности результата кластеризации.
Здесь я не буду обосновывать свой выбор материала. Совокупность, с которой мы работаем, перед вами {взято с https://inside.computerra.ru/}. Почему обложек именно семь, и почему с номера 753-го до 759-го? Отстаньте с глупыми вопросами, метод-то объективный!
Множество классифицируемых объектов:
|
#753 |
#754 |
#755 |
#756 |
#757 |
#758 |
#759 |
|
|
|
|
|
|
|
|







Второй и третий этапы кластеризации: выбор признаков и описание объектов
Нет-нет, я не буду проводить искусствоведческий анализ — хотя бы по причине собственной некомпетентности. Но пример сравнения показать я должен.
«Прямоугольная» матрица (объекты — признаки)
|
|
Метафора |
К-во |
Заголовок |
Обсцентный |
Цвет «…терры» |
Цвет «…терры» |
||
|
R |
G |
B |
||||||
|
#753 |
Меню |
4 |
Нет |
Нет |
Не согласованы |
183 |
0 |
0 |
|
#754 |
Полиграфия |
1 |
Да |
Нет |
Не согласованы |
6 |
105 |
61 |
|
#755 |
Полиграфия |
2 |
Нет |
Нет |
Согласованы |
215 |
0 |
7 |
|
#756 |
Стол |
5 |
Да |
Нет |
Частично согласованы |
176 |
190 |
55 |
|
#757 |
Стена |
1 |
Нет |
Да |
Согласованы |
91 |
24 |
15 |
|
#758 |
Стол |
0 |
Да |
Нет |
Частично согласованы |
97 |
102 |
44 |
|
#759 |
Стена |
1 |
Да |
Да |
Частично согласованы |
177 |
97 |
8 |
Итак, выбираем признаки (характеристики, по которым сравниваемые объекты отличаются друг от друга), и определяем состояния этих признаков для каждого объекта. Первый признак — метафора, положенная в основу изображения. В двух случаях это что-то на столе, в двух — люди у стены, в двух — изображения людей в каких-то полиграфических материалах, и в одном случае это меню. Второй признак — количество людей (в штуках), изображенных на обложках.
Тут мы можем прокомментировать некоторые сложности, связанные с применяемой процедурой. Почему я выбираю те или иные признаки? В шуточной классификации, которую я строю сейчас — «от фонаря». А в серьезной? Старая идея использовать все возможные признаки принципиально нереализуема. Тот их набор, которым располагает любой исследователь, отражает его (и его предшественников) представления о том, что важно, а что — несущественно. «Объективностью» здесь и не пахнет.
Ну хорошо, выбрали мы признаки. А затем нужно однозначно указать их состояния у изучаемых объектов. Но разнообразие действительности и даже объектов классификации далеко не всегда укладывается без искажений в прокрустово ложе наших схематичных представлений. Считать ли изображением человека девушку на игральной карте, и считать ли таковым монстра на другой карте (в случае #753)? А кисть руки в #758 — это человек или нет? В любом случае, использованы будут те решения, которые я вставил в таблицу.
Вы думаете, в «серьезной» систематике описания организмов по принятым признакам являются однозначными? Нет! Очень многое зависит просто от трактовок. Чтобы упростить задачу интерпретации признаков, многие биологи пытаются уйти в классифицирование фрагментов генетических текстов. Сначала выбираем какой-то кусок генетического текста, потом читаем его, потом «выравниваем» последовательности и сравниваем их. Необходимость выравнивания связана с тем, что генетический текст может перебиваться вставками, его куски могут переползать с место на место, etc. Чтобы сравнить куски, имеющие общее происхождение, их надо опознать. Конечно, для этого применяется вполне «объективная» процедура, но при использовании разных алгоритмов она дает разные результаты…
Название темы номера может быть написано сверху на свободном поле, а может быть вставлено в какой-то объект рисунка. В двух обложках присутствует намек на обсцентную лексику. В цветовом отношении наблюдается как согласие цвета, которым набрана часть названия журнала и залиты плашки с анонсами внизу страницы, с фоном, так и большее или меньшее несогласие между ними.
Мне (и, наверное, читателю) уже стало надоедать. Ну что ж, добавим объективности и закончим. Мы можем количественно оценить цвет «…терры». Художник, скорее всего, рисовал в цветовой модели CMYK {описывающей цветовой пространство печати четырьмя красками (голубой, пурпурной, желтой и черной)}, а скачанные из сети обложки конвертированы в RGB {предназначенной для изображений, сформированных светящимися точками трех цветов (красного, зеленого и синего)}, но это не так и важно. Открываю изображения обложек графическим редактором и выписываю значения трех цветовых каналов.
Все! Семь объектов описаны по восьми признакам, «прямоугольная» (потому что количество объектов может не соответствовать — а может и соответствовать — количеству признаков) матрица заполнена.
Четвертый этап кластеризации: сравнение объектов
Нам нужно определить отношение сходства-различия для всех пар объектов, т.е. построить «квадратную» матрицу (объекты-объекты). Существует множество способов решения этой задачи. На самом деле, мы не всегда можем даже твердо ответить на вопрос, какие объекты более похожи друг на друга, а какие отличаются сильнее. Увы, для выбора метрики сходств и различий между классифицируемыми объектами общепринятых (а тем более «объективных») критериев попросту нет.
|
На какой объект более похож объект А: на B или на C? Если использовать в качестве метрики сходства расстояние, то на C: |AC|<|AB|. А если полагаться на корреляцию между показанными на рисунке признаками (которую можно описать как угол между вектором, идущим к объекту из начала координат, и осью абсцисс), то на B: |
|
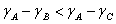 . А как правильно? А единственно правильного ответа нет. С одной стороны, взрослая жаба более похожа на взрослую лягушку (обе взрослые), с другой — на молодую жабу (обе жабы)! Правильность ответа зависит от того, что мы считаем более важным.
. А как правильно? А единственно правильного ответа нет. С одной стороны, взрослая жаба более похожа на взрослую лягушку (обе взрослые), с другой — на молодую жабу (обе жабы)! Правильность ответа зависит от того, что мы считаем более важным.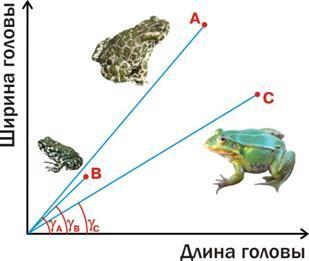
В нашем примере с обложками нам не нужна избыточная сложность, и мы можем попросту использовать сумму отличий между объектами по каждому из 8-ми признаков (а эти отличия высчитывать в долях единицы). Вычислим отличия между #753 и #754. Метафоры разные — отличие на 1. Количество людей различается на 3; это 0,6 от максимального отличия (между #756 и #758). Заголовки в разных местах — 1. Намеков на ругательства нет — 0. Фон и цвет оформления в обоих случаях не согласованы — 0 (в других парах отличия могут составлять также 0,5 или 1). Отличия по красному цвету (R) составляют 177 единиц из 255 возможных, т.е. (с округлением до десятых) 0,7. Аналогично отличия для G составляют 0,4, а для B — 0,2. Итого, обложки #753 и #754 отличаются на 1+0,6+1+0+0+0,7+0,4+0,2=3,9 единиц.
Итак, представляю вам «квадратную» матрицу, показывающую отличия между объектами. Представьте себе, сколько сил мне пришлось потратить, чтоб ее заполнить!
Диагональ этой матрицы заполнять не надо (каждая обложка тождественна сама себе). Из оставшихся клеточек можно заполнить только половину, так как матрица симметрична относительно своей диагонали.
«Квадратная» матрица (объекты — объекты):
|
|
#753 |
#754 |
#755 |
#756 |
#757 |
#758 |
#759 |
|
#753 |
— |
3,9 |
2,5 |
3,4 |
4,2 |
4,3 |
4,5 |
|
#754 |
|
— |
3,6 |
3,3 |
4,8 |
2,2 |
3,4 |
|
#755 |
|
|
— |
4,2 |
2,8 |
3,9 |
4,2 |
|
#756 |
|
|
|
— |
5,3 |
1,6 |
3,4 |
|
#757 |
|
|
|
|
— |
3,1 |
2,1 |
|
#758 |
|
|
|
|
|
— |
2,6 |
|
#759 |
|
|
|
|
|
|
— |
Можно ли было высчитывать отношения между объектами как-то иначе? Ну конечно! Мы могли трактовать состояния признаков как координаты, и вычислить евклидово расстояние между объектами в таком пространстве. А еще мы могли использовать квадрат или корень евклидова расстояния. Использованная нами метрика напоминает сумму отличий по каждой координате — манхэттеновское расстояние, или «расстояние между городскими кварталами», только нормированное в долях единицы. А еще есть разные меры корреляции и ассоциации. Как выбирать между ними? Или из соображения удобства (как в нашем примере), или на основании вкуса и традиции…
Пятый этап: собственно кластеризация
Наша задача — объединить наиболее похожие (т.е. наименее отличающиеся) объекты в кластеры. Какая пара объектов более всего похожа? Конечно, #756 и #758, они отличаются всего на 1,6 единиц из 8 возможных (и основной вклад в это отличие вносит различное количество людей на обложке). Значит, мы объединяем эти два объекта в один: (#756+#758).
А вот теперь нам надо ответить на очень существенный вопрос. Как определить расстояние от единичного объекта до кластера? К примеру, #753 отстоит от #756 на 3,4 единицы, а от #758 — на 4,3 единицы. Каково расстояние от #753 до (#756+#758)?
Мы можем сказать, что расстояние от точки до кластера — это расстояние до ближайшей точки данного кластера (такой вариант называется присоединением по наибольшему сходству). А может, наоборот, до самой удаленной (полное присоединение)? А может, высчитывать среднее значение? В одних ситуациях логичнее одно, в других — другое. Присоединение к ближайшему соседу порождает лентообразные, цепочечные кластеры. Полное присоединение бьет совокупность на относительно небольшие кластеры нижнего уровня. Присоединение по среднему дает определенный компромисс. А есть еще присоединение по Уорду, когда для объединения объекта с кластером выбирается такой вариант, при котором приращение внутрикластерной суммы квадратов отклонений оказывается минимальным… Как выбирать между этими вариантами? «Объективного» критерия нет, и тот или иной выбор, как и в предыдущем случае — дело вкуса и традиции. Остается только напомнить, что сверхидея использования кластерного анализа в биологии — избавить науку от влияния вкуса и традиции.
В зоологических исследованиях хорошие результаты часто получаются при использовании евклидовой метрики, а также присоединении по Уорду или по среднему сходству. Высчитывать суммы квадратов очень хлопотно, поэтому мы воспользуемся присоединением по среднему сходству. Теперь мы можем перестроить «квадратную» матрицу для шести объектов:
«Квадратная» матрица после первого шага кластеризации
|
|
#753 |
#754 |
#755 |
(#756+#758) |
#757 |
#759 |
|
#753 |
— |
3,9 |
2,5 |
3,85 |
4,2 |
4,5 |
|
#754 |
|
— |
3,6 |
2,75 |
4,8 |
3,4 |
|
#755 |
|
|
— |
4,05 |
2,8 |
4,2 |
|
(#756+#758) |
|
|
|
— |
4,2 |
3,0 |
|
#757 |
|
|
|
|
— |
2,1 |
|
#759 |
|
|
|
|
|
— |
Для новообразованного кластера в каждой ячейке стоит арифметическое среднее тех расстояний, которые разделяли остальные объекты с его элементами.
Какой шаг следующий? Объединить #757 и #759 на уровне 2,1 единиц. Снова перестраиваем «квадратную» матрицу.
«Квадратная» матрица после второго шага кластеризации
|
|
#753 |
#754 |
#755 |
(#756+#758) |
(#757+#759) |
|
#753 |
— |
3,9 |
2,5 |
3,85 |
4,35 |
|
#754 |
|
— |
3,6 |
2,75 |
4,1 |
|
#755 |
|
|
— |
4,05 |
3,5 |
|
(#756+#758) |
|
|
|
— |
3,6 |
|
(#757+#759) |
|
|
|
|
— |
Объединяем #753 и #755 на уровне 2,5 единиц. Наверное, приводить перестроенную матрицу уже не нужно — внимательному читателю понятно, как я ее получаю. Следующий шаг — присоединение #754 к (#756+#758) на уровне 2,75. Если я не ошибся в расчетах, (#754+#756+#758) объединяется с (#757+#759) на уровне 3,6, а затем (#754+#756+#757+#758+#759) кластеризуется с (#753+#755) на уровне приблизительно 3,84. Все!
Шестой этап: анализ полученных кластеров
|
|
|
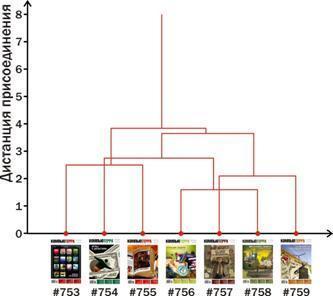
Рядом с деревом, где обложки стоят в порядке их номеров, приведен результат вращения в его узлах (смотрите, дерево «перебирало ногами», как паук, который запутался сам в себе, и еле-еле распуталось). В результате такой перестройки полученная классификация стала восприниматься намного легче.
А допустима ли такая перестройка полученного результата классификации? Да. Кластерная структура отражает только те отношения сходства и отличия объектов, которые представлены в ней явно. В полученном дереве не содержится информации об уровне сходства #754 и #755, в нем есть только информация об уровне сходства включающих их кластеров.
Ну что, получилось интересно. Обложки разделились на «коричневатые-стенные-ругательные», «зеленоватые-(настольные и долларовые)» и «красноватые». Не знаю, получится ли это у читателя, а я сам, кластеризовав эти обложки, смог увидеть их по-новому.
Насколько надежен полученный результат? Для ответа на этот вопрос есть несколько подходов. Упомяну только один. Выкидываем один из объектов или добавляем еще один (обложку #760). Сильно или нет изменился результат? Выкидываем один из признаков или добавляем еще один (количество слов в названии темы номера). Как теперь? Из ответов на эти вопросы складывается общая оценка полученной классификации.
В целом можно сказать следующее. Когда в структуре сходств и отличий изучаемых объектов отражены несколько различных уровней их группирования во включающие друг друга группы, кластерный анализ оказывается способен красиво показывать такую структуру. Например, если мы сравниваем организмы разных, хорошо отличающихся видов, принадлежащих, например, к разным семействам и разным классам, кластерный анализ сработает на отлично. Там, где уровни видовых, родовых и семейственных отличий отличаются несильно, или данные вообще бесструктурны, кластерный анализ все равно построит какое-то дерево. Увы, это дерево будет неустойчиво и бесполезно.
Некоторые мировоззренческие следствия
Для начала зададимся вопросом, однозначен ли (при выбранной метрике) переход от «прямоугольной» матрицы к «квадратной». Конечно, да. Можно ли по «квадратной» матрице восстановить «прямоугольную»? Нет. Одному и тому же набору дистанций между изучаемыми объектами соответствует множество вариантов распределения их признаков. На четвертом этапе кластерного анализа происходит значительная потеря информации о свойствах объектов, и такая же потеря происходит и на каждом шаге пятого этапа.
Итак, в итоговом дереве отражена лишь часть информации о результатах сравнения объектов. Да-да, это самая характерная часть… но всего лишь часть. Остальное выкинуто. А если бы кластеризация шла по другому пути, выкинута была бы иная часть информации.
Что и кто определяет, какая часть эмпирического знания о подобиях и различиях объектов отразится в классификации? Что — алгоритм, случайности его срабатывания на данном наборе объектов и признаков. Кто — исследователь, выбравший классифицируемое множество, признаки для его описания, вогнавший действительное разнообразие объектов в принятый набор состояний признаков, а также применивший ту или иную метрику и тот или иной способ присоединения. Осознает ли это типичный фенетический систематик? Обычно нет — он же использует «объективный» метод!
Мы установили, что кластерный анализ надежно отражает лишь ту иерархию групп, которая хорошо отражается в структуре сходств и различий классифицируемых объектов. Но такую структуру отразит и система, построенная эволюционным, «эклектичным» систематиком! Он постарается выстроить объекты так, чтобы их положение в системе максимально хорошо отражало свойства, которые он считает важными, а также согласованно изменяющиеся признаки. Выстраивая такую систему, он может опираться на свои представления о родстве изучаемых объектов, но он будет рассматривать эти представления лишь как один из источников информации. Увы, частью сведений о рассматриваемых объектах придется пожертвовать, не отразив ее в классификации. Ничего страшного, ведь такой выбор будет делаться осознанно, на основании опыта изучения данной группы!
Поиск обложки-предка
После того, как я классифицировал обложки «КТ» методами фенетики, я почувствовал, что без обращения к кладистике мое изложение будет неполным. С некоторым опасением (кладистика имеет немало экзальтированных сторонников) ступаю на эту зыбкую почву…
Важнейшей идеей Вилли Хеннига было решение реконструировать родство не по всем сходным признакам объектов, а лишь по тем, которые отличают группы родственников от их общих предков {в кладистике такое сходство называется сходством по синапоморфиям, и принципиально отличается от сходства по унаследованным от общего предка признакам (симплезиоморфиям) или по независимо приобретенным особенностям (ложным синапоморфиям). Уникальные особенности классифицируемого объекта (аутапоморфии) тоже не представляют интереса для систематиков-кладистов}. Для этого надо установить какое состояние каждого признака является для классифицируемой совокупности объектов исходным, а какое — продвинутым. Решать эту задачу можно по-разному. Лучший вариант — выбрать какой-нибудь родственный объект из другой («сестринской») группы, и считать характерные для него состояния признаков исходными. Следуя этой логике, я долго рассматривал обложки «Домашнего компьютера» («родственника» КТ), пытаясь найти среди них ту, которая отражала бы исходное состояние использованных мной признаков. Увы, я не смог сделать «объективный» выбор и еще более восхитился кладистами, которые на это способны. Я решил воспользоваться иным, «онтогенетическим» критерием.
Когда художник начинает рисовать обложку, в ней еще не использована никакая метафора, нет ни людей, ни намеков. А какой цвет надписи следует считать исходным? Черный, R 0; G 0; B 0! Признаки, которые могут принимать несколько значений, мы разбиваем на простые, выражаемые или нолем (исходное значение) или единицей (продвинутое состояние). Интенсивность каждого из цветовых каналов оцениваем в три {а «объективный» ли критерий использован для выделения именно трех градаций этих признаков? Объективный! Дело в том, что 255 делится на 3 (по 85 на шаг), и это деление соответствует логике «мало—средне—много». Кроме того, многие сторонники кладистики считают, что использование "объективного" метода дает им индульгенцию чуть не на любые произвольные решения} шага, от отсутствия или слабого до максимальной насыщенности. Ни на одной из обложек синий канал не насыщенней трети (85). Раз объекты не отличаются по этому признаку, мы исключаем его от анализа. Выбранное решение произвольно? Да. Но, поймите, произвольным будет любое решение, так что наше не хуже других!
Описание классифицируемых объектов для кладистического анализа
|
|
Метафора |
Количество |
Заголовок |
Обсцентный |
Согласованность цвета «…терры» и фона |
Цвет «…терры» |
|||||||||||||
|
R |
G |
||||||||||||||||||
|
Меню |
Полиграфия |
Стол |
Стена |
1 |
2 |
3 |
4 |
5 |
Частичная |
Полная |
<85 |
>85 |
>170 |
<85 |
>85 |
>170 |
|||
|
#753 |
1 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
0 |
0 |
0 |
|
#754 |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
|
#755 |
0 |
1 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
|
#756 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
1 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
|
#757 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
|
#758 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
1 |
1 |
1 |
1 |
1 |
0 |
|
#759 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
0 |
1 |
1 |
1 |
1 |
1 |
0 |
При установлении предполагаемого хода эволюции, в кладистике принимается несколько аксиом, из которых мы упомянем две. Во-первых, когда один вид порождает другой, вид-предок должен прекратить существование, чтобы появилось два равноправных вида-потомка. Во-вторых, эволюция должна идти наиболее экономным путем: из двух филогенетических деревьев (кладограмм) следует выбирать то, которое предусматривает минимум прямых и возвратных изменений. Проверка этих аксиом, когда она оказывается возможной (например, при наличии хорошей палеонтологической летописи) показывает, что эволюция обычно идет иначе. И виды-предки благополучно живут рядом со своими потомками, и параллелизмы с конвергенциями (по крайней мере в морфологической эволюции) являются нормой, а не исключениями. Почему же кладистики настаивают на этих аксиомах? Потому что без их принятия «объективный» метод не срабатывает! Парадокс? В кладистике немало таких аксиом, удивляться тут нечему.
Итак, к букету произвольных решений, необходимых для построения фенетической классификации, кладистики добавляют еще ряд уязвимых для критики допущений.
Ну что, беру кладистические программы. Одна используется для ввода описания объектов. Другая — для построения кладограмм. Третья — для просмотра этих кладограмм (сторонники кладистики не боятся трудностей). Разобраться бы с командной строкой в user-hostile интерфейсе… Пропущу детали и расскажу о результате.
Умная программа сама выкинула из рассмотрения несколько избыточных признаков, построила 945 кладограмм и выбрала из них 39 минимальных — предусматривающих по 29 «эволюционных шагов» каждая. Приведу для примера две из них. Наши исходные данные не отражали такое распределение сходств и различий, какое характерно для объектов, связанных общим происхождением, и поэтому кладограммы получились многочисленными и невыразительными. Так, одновременное разделение на три ветви, отраженное в обоих показанных на рисунке кладограммах, говорит о том, что алгоритм не разобрался в ранних этапах «эволюции» данной группы (и «винить» его за это не следует — данные, как-никак, искусственные).
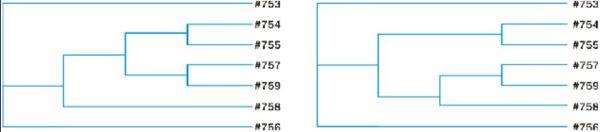
Да, получилось невыразительно. Кладистический анализ хорошо работает в тех случаях, когда искомая структура (след истории) хорошо отражается в материале. Стоит ли говорить, что и традиционные методы в такой ситуации тоже увидят этот след? Впрочем, кладистика позволяет переложить разгребание больших массивов данных на программу, что, конечно, неплохо. Кстати, и сами кладистики сочтут удачным тот результат, который будет соответствовать традиционным взглядам на эволюцию изучаемой группы. А в чем тогда выразится новизна их работы? Конечно, в получении традиционной системы «объективными» методами!
Торжество демократии в науке
Прервалась ли линия Аристотеля-Линнея-Геккеля-Майра в биологической систематике? Один мой коллега публично утверждает, что да. «Сегодня нет ни одного ученого, который бы работал в компромиссной парадигме!». Как ни парадоксально, такая позиция совершенно неуязвима. Когда этому коллеге приводишь примеры живых и авторитетных людей, работающих в этом русле, он отвечает: «Это не ученые, это маразматики! Сегодня наукой может считаться лишь то, что отвечает объективной методологии кладистики».
…Молодая преподавательница предоставляет на рассмотрение кафедры программу спецкурса, где упоминаются взгляды нескольких московских палеонтологов {речь идет о высоко мною ценимых А.П. Расницыне и А.С. Раутиане, а также о ныне покойном В.В. Жерихине} на эволюцию биологических сообществ. Коллега-кладист настаивает на удалении из программы любого упоминания о взглядах этих ученых. Объяснение таково. В рамках эволюционной систематики мнение авторитета, глубоко разобравшегося в разнообразии какой-то группы, обычно воспринимают внимательнее, чем мнение начинающего исследователя. Это может приводить к «зажиму» мнения молодых ученых. Значит, традиционная систематика авторитарна, а «объективная» кладистика — демократична. Цитируемые ученые не одобряют кладистику. Значит, они потенциально виновны в ущемлении мнения научной молодежи. Хотя эти ученые и упоминаются в связи с иной проблемой, мой уважаемый коллега требует запретить молодой сотруднице излагать не просто излагать взгляды, а даже упоминать имена противников демократии. Думаете, это шутка? Если бы!..
В какой-то степени оплотом эволюционных систематиков является российская наука, а среди западных ученых восторжествовала кладистика. У этого феномена есть несколько возможных объяснений. Одно (любимое кладистами) — «отсталость» российской науки и прогрессивность западной. Второе объяснение связывает разницу в подходах с особенностями финансирования исследований.
Получая грант, западный ученый должен расписать график выполняемых работ. На первом этапе делаем то-то, на втором — то-то, а такой-то результат предъявляем к концу отчетного периода. Формализованный кладистический подход позволяет легко спланировать такие действия. Наберем такие-то категории признаков, забросим их в программу и получим результат. Спланировать действия «эклектичного» систематика намного сложнее. Там, где ученый живет от гранта до гранта, он будет пользоваться подходящей методологией. А в России (и вообще в Советском Союзе и на постсоветском пространстве) до последнего времени ученые люди сидели на зарплате. Большая часть из них не делала ничего, а некоторые (вероятно, от безделия) начинали задумываться о том, как выполнить свою задачу лучшим возможным образом. Вот такие нарушители правил зачастую отказывались от жестких рамок кладистики. Кстати, и сам Вили Хенниг придумал кладистику не в рамках проектной работы, а скорее в рамках размышлений о том, что прямо не относилось к его задачам…
И все же я думаю, что традиционная систематика на третьем тысячелетии своей истории находится в расцвете сил, сколькими бы головами {поиск научной истины путем подсчета количества сторонников той или иной точки зрения напоминает мне процедуру подсчета скота по головам} не были представлены ее сторонники, и как бы не препятствовало современное финансирование науки ее развитию. Почему? Сейчас объясню.
Несколько слов о пользе «эклектики» и компромиссов
Как вы уже поняли, сейчас популярны несколько «объективных» методов систематики. Эти методы позволяют перерабатывать большие массивы фактов. Одни из таких методов дают отчетливую картину распределения отношений сходства и различия, другие — демонстрируют отношения родства. Использование этих данных позволит найти оптимальный компромисс, который даст возможность построить лучшую систему из возможных. Как ни парадоксально, «объективные» школы усиливают своими успехами школу своих противников, с благодарностью принимающую любые ценные сведения об изучаемых объектах. Чем полнее будет наша картина знания о классифицируемых объектах, тем лучше будет тот компромисс, который мы найдем.
А претензии «объективных» методов на исключительность? Думаю, они со временем отомрут. Не нужно слишком обижаться на тех пылких сторонников молодых научных школ, которые, схватившись за какой-то один аспект действительности, отрицают все остальные. Повзрослеют, излечатся от детских болезней… Именно поэтому, являясь сторонником компромиссной систематики, я считаю нужным изучать и методы фенетической систематики, и методы кладистики. В дело пойдет все!
Да, кстати, а как правильно классифицировать обложки «Компьютерры»? Единой, истинной системы нет. Естественной следует считать такую систему, которая полнее всего отражает сущностные свойства объектов с точки зрения того применения, для которого эта система создается. Возможные предназначения биологической классификации — тема отдельного разговора. А для читателей и сотрудников «КТ», вероятно, самым удобным является способ классифицирования обложек по порядку их номеров — тот самый, с которого мы начали.
Так что, наши многословные рассуждения были бессмысленны?! Надеюсь, что нет — они стали поводом задуматься об общих вопросах. Всего доброго!
Эта статья была подготовлена для печати в "Компьютерре", но не была опубликована из-за избыточного, по журнальным меркам, объема. Главред журнала посоветовал мне сделать блог и выложить эту статью туда. Прошло совсем немного времени, и я последовал его совету...