|
||||
|
← |
Д.А. Шабанов, М.А.Кравченко. Статистический анализ данных в зоологии и экологии |
→ |
||
|
Тема 4. Сравнение выборок |
||||
|
Биостатистика-04 |
Биостатистика-06 |
|||
Тема 4. Сравнение выборок
4.1. В каких ситуациях может понадобиться сравнивать выборки?
Значительная часть статистических исследований соответствует одной простой схеме. Очень часто бывает необходимо установить, к одной генеральной совокупности принадлежат две выборки, или к разным. Приведем примеры таких исследований.
— Собраны выборки определенных животных из ряда точек. Следует определить, есть ли между ними существенная разница, позволяющая говорить, что они относятся к разным видам. Вопрос можно переформулировать и так: относятся эти выборки к одной генеральной совокупности, или к разным?
— Влияет ли пол особей на длину их хвостов (т.е. отличаются ли особи разного пола по длине хвостов)? Иная формулировка проблемы: можно ли считать, что значения данного признака у особей разного пола представляют собой выборки из разных генеральных совокупностей (хвостов самок и хвостов самцов) или их можно рассматривать как выборку из одной совокупности (хвостов особей данного вида без учета их пола).
— Как влияет на определенный признак какой-то фактор (например, одинакова ли выживаемость экспериментальных животных в чистой воде и в смеси чистой воды с водопроводной водой)? Являются ли выборки экспериментальных животных, развивавшихся в чистой и исследуемой воде, выборками из разных совокупностей?
— Улучшает ли новое лекарство состояние больных по сравнению с состоянием тех, кто, страдая такими же болезнями, получает традиционное лечение? Из одной или разных генеральных совокупностей получены выборки больных, которых лечили традиционно и новыми методами?
Итак, по составу выборок следует понять, из одной генеральной совокупности или из разных они взяты. Такое сравнение вполне соответствует шуточному примеру, использованному для обсуждения понятия статистической значимости в первой теме.
4.2. Сравнение выборок по Стьюденту
В 1908 году английский математик В. Госсет, который работал в пивной компании и публиковал свои работы под псевдонимом Стьюдент, описал функцию, по которой значения выборочной средней распределены вокруг значения средней генеральной совокупности. Для больших выборок распределения выборочных средних носят нормальный характер, а для маленьких выборок — более пологи.
Пользуясь этой функцией, можно определить, какова вероятность того, что две выборки взяты из одной генеральной совокупности. При этом вычисляется t-критерий, или критерий Стьюдента. 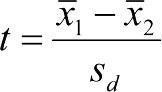 . В этой формуле в числителе находится разность средних, а в знаменателе — ошибка этой разности.
. В этой формуле в числителе находится разность средних, а в знаменателе — ошибка этой разности.
При равенстве количества объектов в выборках (n1 = n2 = n) вычисление ошибки разности средних оказывается относительно более простым, чем в следующем случае. Она вычисляется как корень из суммы квадратов стандартных отклонений сравниваемых выборок:
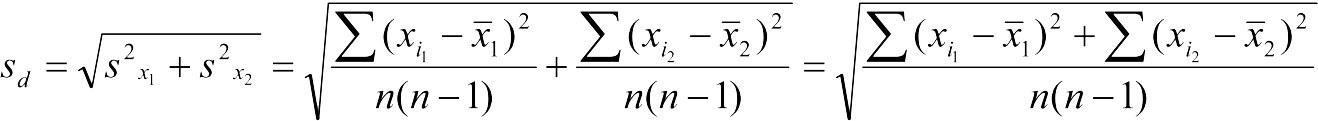 .
.
Если численности сравниваемых выборок разные, тогда 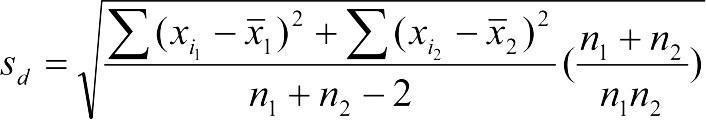 .
.
Для каждого числа степеней свободы df (df = n1 + n2 - 2) критерий Стьюдента принимает тем более высокие значения, чем существеннее отличия между выборками. Их сравнивают с табличными значениями и определяют уровень статистической значимости зарегистрированных результатов.
Пример такой таблицы:
Критические значения t-критерия Стьюдента при различных уровнях статистической значимости
|
Число степеней свободы df |
p |
Число степеней свободы df |
p |
||||
|
0,05 |
0,01 |
0,05 |
0,05 |
0,01 |
0,001 |
||
|
1 |
12,71 |
63,66 |
64,60 |
4 |
2,78 |
4,60 |
8,61 |
|
2 |
4,30 |
9,92 |
31,60 |
5 |
2,57 |
4,03 |
6,87 |
|
3 |
3,18 |
5,84 |
12,92 |
6 |
2,45 |
3,71 |
5,96 |
Итак, алгоритм «ручного» использования критерия Стьюдента весьма прост: для двух выборок определяются их средние, вычисляется критерий Стьюдента, а затем по таблицам (для соответствующего числа степеней свободы) определяется уровень статистической значимости зарегистрированных отличий.
Вследствие своей простоты критерий Стьюдента стал использоваться очень широко, значительно шире, чем следовало бы. Дело в том, что по своей сути он требует, чтобы сравниваемые выборки имели нормальное распределение. В любом случае, разобраться, как работает этот критерий, необходимо. Давайте сравним с его использованием длину тела самцов и самок лягушек, описанных в файле Pelophylax_example.sta.
Чтобы вызвать один из вариантов анализа выборок с использованием критерия Стьюдента, мы должны пройти по пути Statistics / Basic Statistics.
Рис. 4.2.1. Меню Statistics
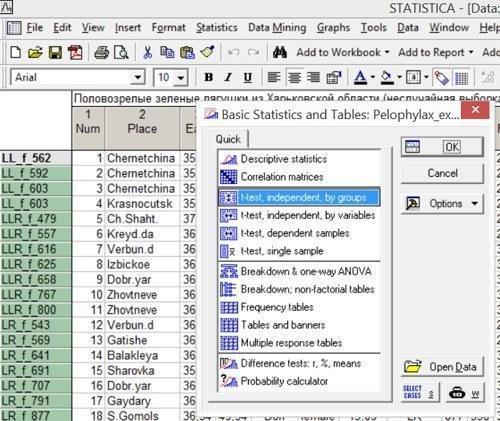
Рис. 4.2.2. Меню Statistics / Basic Statistics
В меню Statistics / Basic Statistics надо выбрать подходящий вариант сравнения выборок по критерию Стьюдента. В предлагаемом окне есть четыре варианта такого сравнения.
Варианты применения критерия Стьюдента
|
Название |
Пиктограмма |
Применение |
|
t-test, independent, by groups |
Две группы данных одна над другой |
Однотипные измерения в одном столбце, разделенные на группы значениями в другом столбце |
|
t-test, independent, by variables |
Две группы данных в соседних столбцах, не обязательно соответствующие друг другу (могут различаться по численности) |
Измерения в двух разных столбцах |
|
t-test, dependent samples |
Соответствующие друг другу (равной численности) две группы данных в соседних столбцах |
Парные сравнения (например, сравнение длин правой и левой руки у разных людей) |
|
t-test, single sample |
Отдельная группа данных |
Отличия среднего значения группы данных от какого-то значения (например, от 0) |
Естественно, наш случай соответствует варианту «t-test, independent, by groups». Понятно, что Dependent variables (величина или величины, изменчивость которых анализируется), это переменная L, а Grouping variable — переменная Sex, содержащая те значения, которые разбивают значения переменной L на группы, соответствующие самкам и самцам.
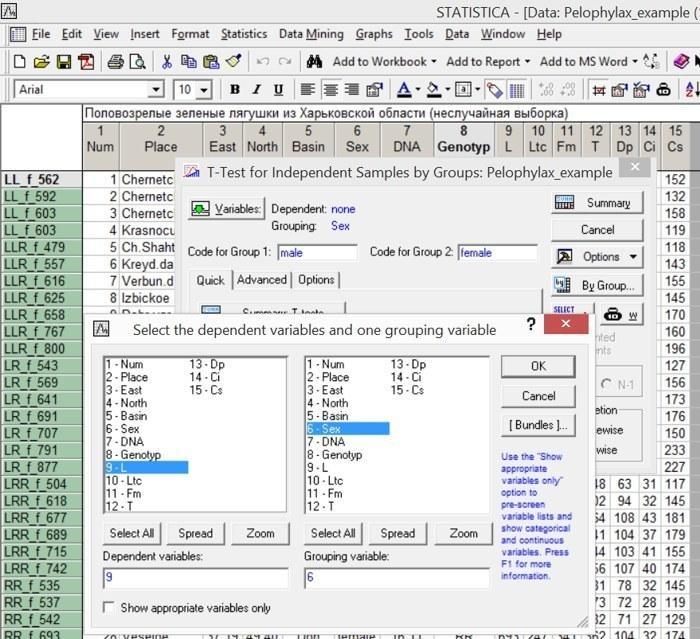
Рис. 4.2.3. Диалог T-Test Independent Sample by Groups
При нажатии на кнопку Summary, расположенную в правом верхнем углу диалога T-Test Independent Sample by Groups, программа откроет отдельную страницу с результатами анализа.
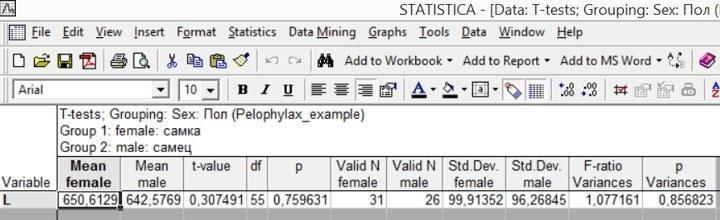
Рис. 4.2.4. Результат анализа
Таблицу с результатами, показанную на рис. 4.2.4, надо рассмотреть подробнее. Рассмотрим все ее столбцы по порядку.
Variable — переменная, для которой приводятся данные (если бы мы указали несколько Dependent variables, в таблице было бы несколько строк).
Mean female — Среднее значение для первой выборки.
Mean male — Среднее значение для второй выборки.
t-value — Значение критерия Стьюдента (для определенного количества степеней свободы его можно сравнить с табличными значениями).
df — Количество степеней свободы.
p — Уровень статистической значимости отличий сравниваемых выборок по критерию Стьюдента.
Valid N female — Численность первой выборки.
Valid N male — Численность второй выборки.
Std. Dev. female — Стандартное отклонение первой выборки.
Std. Dev. male — Стандартное отклонение второй выборки.
F-ratio Variances — Критерий Фишера: отношение большей дисперсии (квадрата стандартного отклонения) к меньшей дисперсии.
p Variances — Уровень статистической значимости отличий сравниваемых выборок по критерию Фишера.
В поисковых биологических исследованиях принято, что основанием для принятия альтернативной гипотезы (и отклонения нулевой) является уровень статистической значимости меньший, чем 0,05. Что это означает в случае сравнения по критерию Стьюдента? Что такие отличия средних значений, как те, что были зарегистрированы, возникают в силу случайности при формировании выборок не чаще, чем с вероятностью 0,05 (т.е. не чаще, чем в одном случае из двадцати). В нашем примере р=0,76. Это означает, что такие же отличия, как те, что мы зарегистрировали, возникают более, чем в трех четвертях случаев просто в результате случайности при формировании выборок. Такие отличия статистически незначимы. Оснований для отклонения нулевой гипотезы нет.
Означает ли это, что длина тела самок и самцов зеленых лягушек не отличается? Нет. На самом деле, на основании анализа намного более широких выборок можно утверждать, что самки зеленых лягушек крупнее самцов. Однако в данном исследовании, на рассмотренном материале отличия оказались статистически незначимыми. Увеличив выборку в несколько раз или рассматривая более однородный материал (например, представителей одного и того же генотипа из одного местообитания) мы, скорее всего, получили бы статистически значимые различия.
4.3. Использование критерия Фишера для сравнения выборок
Как вы видите, результаты проведенного нами сравнения выборок, показанного на рис. 4.3.4, включают также вычисление меры изменчивости (стандартных отклонений) и критерия Фишера (отношения дисперсий). Этот критерий предложен американским статистиком Джорджем Снедекором, который назвал его в честь Фишера. Это тот же самый критерий, который используется в дисперсионном анализе (рассматриваемом с следующей теме), однако в данном случае он применяется для иных целей.
Прежде всего, надо понять, с чем связано использование критерия Фишера.
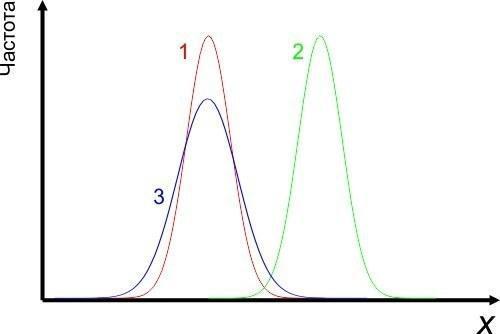
Рис. 4.3.1. Сравнение трех распределений. Распределения 1 и 2 отличаются по средним значениям, а 1 и 3 — по уровню изменчивости
Как уже было сказано, сравнение по Стьюденту — параметрический метод, который основывается на предположении, что совокупности, из которых получены сравниваемые выборки, имеют нормальное распределение. Нормальные распределения (см. пункт 1.5) задаются двумя параметрами: : 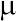 (генеральным средним) и
(генеральным средним) и 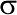 (генеральным стандартным отклонением). Если два нормальных распределения отличаются друг от друга, значит у них отличаются или средние, или стандартные отклонения (или и то, и другое вместе). Поэтому, чтобы определить вероятность того, что сравниваемые выборки получены из одной генеральной совокупности, надо сравнить и их средние значения, и их меры изменчивости.
(генеральным стандартным отклонением). Если два нормальных распределения отличаются друг от друга, значит у них отличаются или средние, или стандартные отклонения (или и то, и другое вместе). Поэтому, чтобы определить вероятность того, что сравниваемые выборки получены из одной генеральной совокупности, надо сравнить и их средние значения, и их меры изменчивости.
В рассмотренном нами примере уровень статистической значимости отличий сравниваемых выборок по критерию Фишера также ниже критического; р=0,86.
4.4. Диаграммы размаха в модуле t-теста
Из окна диалога T-Test Independent Sample by Groups можно вызвать не только окно с числовыми результатами сравнения данных, но и график, позволяющий сравнить два распределения. При нажатии на кнопку Box & whisker plot программа построит следующую диаграмму размаха.
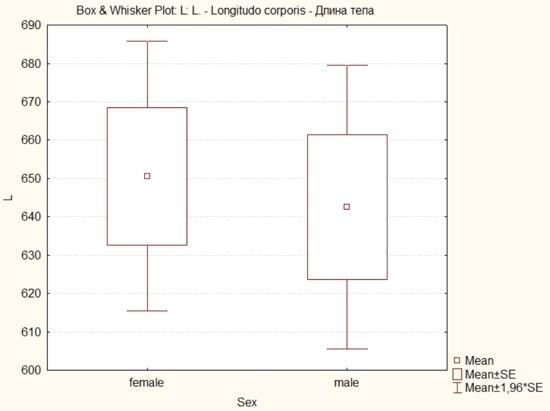
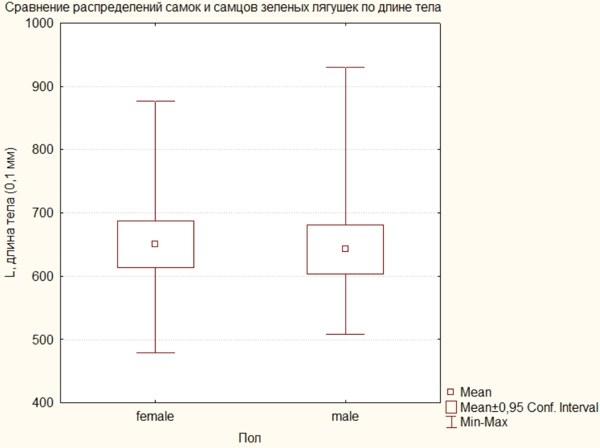
Рис. 4.4.1. Диаграмма размаха, построенная по данным о длине тела самок и самцов лягушек
Расшифровки обозначений приведены рядом с графиком. Точка посредине каждой «коробки» обозначает среднее значение каждой выборки, «стенки коробки» — среднее плюс-минус стандартную ошибку (SE), а «усы» — среднее плюс-минус SE, умноженная на 1,96. Стандартная ошибка (Standard Error) — мера изменчивости, определяемая как 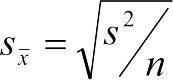 . Ее использование не рекомендуется современными руководствами по статистике; почему в данном модуле применяется именно она, не очень понятно. Более «качественной» мерой для оценки изменчивости исследуемой величины является доверительный интервал (высчитываемый для определенного уровня статистической значимости). Доверительный интервал (Confidence intervals) показывает пределы, в которых с заданной вероятностью находится среднее генеральной совокупности, оцениваемое по изменчивости взятой из этой совокупности выборки.
. Ее использование не рекомендуется современными руководствами по статистике; почему в данном модуле применяется именно она, не очень понятно. Более «качественной» мерой для оценки изменчивости исследуемой величины является доверительный интервал (высчитываемый для определенного уровня статистической значимости). Доверительный интервал (Confidence intervals) показывает пределы, в которых с заданной вероятностью находится среднее генеральной совокупности, оцениваемое по изменчивости взятой из этой совокупности выборки.
Чтобы показать на диаграмме размаха иные меры, чем те, которые показаны там по умолчанию, надо щелкнуть на графике правой кнопкой мыши, выбрать опцию Graph Properties (All Options)…, в открывшемся окне выбрать закладку Plot: Box/Whisker, а там — кнопку More (восхищаясь при этом, как глубоко запрятаны важные настройки).
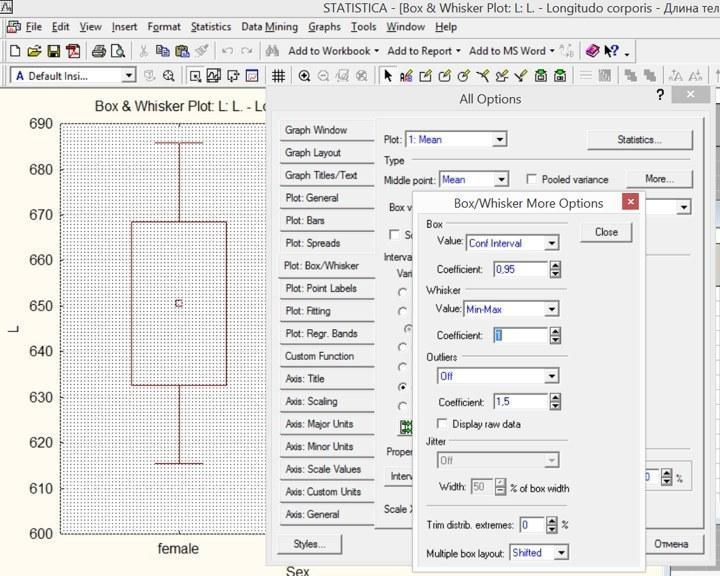
Рис. 4.4.2. Редактирование диаграммы размаха, построенной по данным о длине тела самок и самцов лягушек
В открывшемся окне можно, например, задать для коробки значения доверительного интервала, а для усов — минимального и максимального значения (не забыв при этом исправить коэффициент 1,96, на который будут умножаться эти величины, заменив его на 1).