 |
||||
|
← |
Д. Шабанов, М. Кравченко. «Статистичний оракул»: аналіз даних в зоології та екології |
→ |
||
|
Тема 5(S). Візуалізація даних у Statistica |
|
|||
|
«Статистичний оракул»-04 |
«Статистичний оракул»-05(S) |
«Статистичний оракул»-06 |
||
Тема 5. Візуалізація даних у Statistica
5.1. Гістограми в Statictica: приклад побудови графіків
Ви починаєте вивчення даних у певному файлі... Який крок має бути першим? Найчастіше — візуалізація, побудова графіків. Розглянемо її, починаючи з самого простого типу графіків: гістограми. Вони викликаються з меню Grafs (Графіка), і знаходяться там як в самому верху списку, так і викликаються з більш «глибоких» меню.
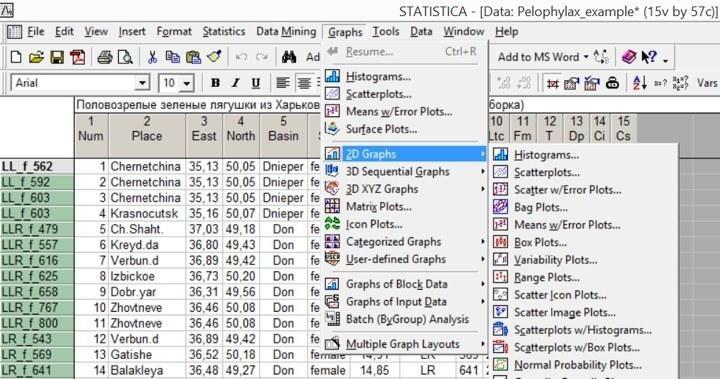
Рис. 5.1.1. Викликати режим побудови гістограм можна і безпосередньо з меню «Графіка», і з підміню двомірних графіків (2D Graphs), що надає ширший вибір опцій
Гістограми показують частоти об'єктів, що відносяться до різних класів, у вигляді стовпців. Наприклад, суттєвою ознакою, за яким можна групувати описаних у файлі жаб, є їх генотип. Побудуємо розподіл жаб по генотипам. Пройшовши по шляху Grafs / Histograms ... (Графіка / Гістограми ...) або, що те ж саме, Grafs / 2D Grafs / Histograms ..., ми потрапляємо в «швидкий» діалог побудови гістограм.
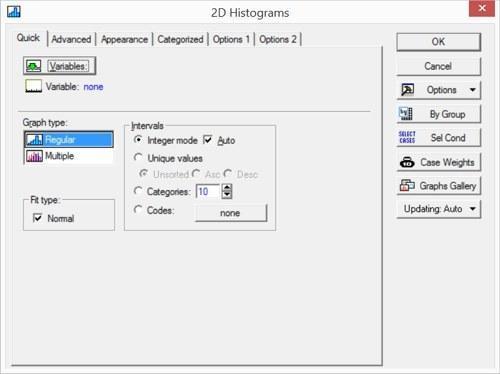
Рис. 5.1.2. Швидкий діалог побудови гістограм
Натиснувши кнопку Variables (Змінні), виберемо там змінну Genotyp. У цій вкладці можна вибрати і кілька змінних (і, в найпростішому випадку, побудувати одночасно кілька графіків). Щоб вибрати змінні, що знаходяться не поряд один з одним, слід під час вибору утримувати клавішу Ctrl. Прапорець біля віконця Fit type: Normal (Тип підгонки: Нормальне) додасть на графік криву нормального розподілу (найкращим чином наближену до наявних даних). В даному випадку це зовсім не потрібно, так що цей прапорець варто зняти. Також правильно зняти прапорець у віконці Auto, що забезпечує автоматичне розбиття діапазону значень змінної Genotyp (хоча в даному випадку це не вплине на результат: все одно ця змінна приймає тільки значення 1, 2, 3, 4 і 5).
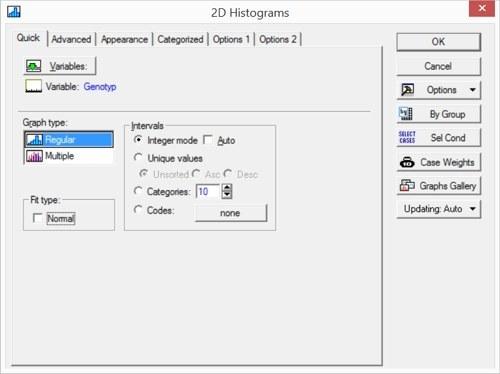
Рис. 5.1.3. Швидкий діалог побудови гістограм: необхідні корективи внесені
Вкладка Advanced (Додатково) надає більш широкі можливості для управління властивостями гістограми.
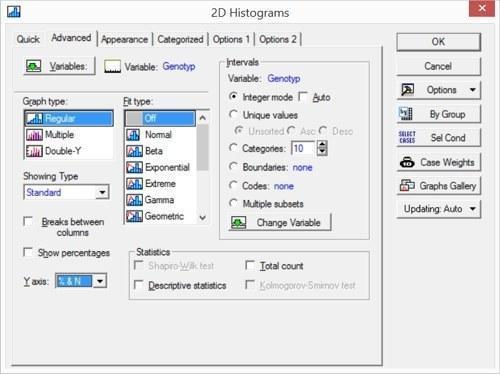
Рис. 5.1.4. Вкладка «Додатково» в діалозі побудови гістограм
Поміняємо в ній режим відображення осі Y: вкажемо там опцію «% & N», щоб бачити там розподіл жаб по генотипам не тільки по штукам, а й у відсотках від загальної кількості. Натиснувши кнопку «ОК», отримаємо результат.
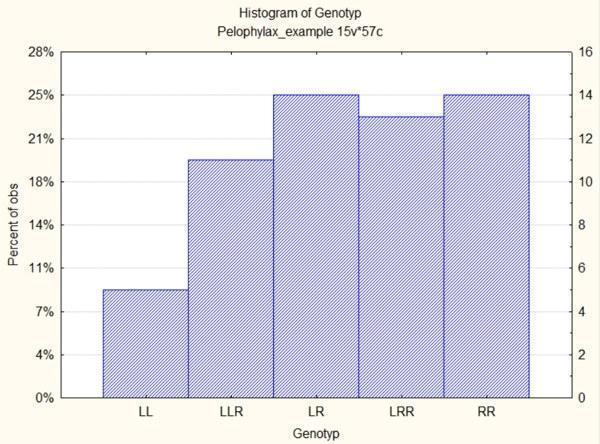
Рис. 5.1.5. Розподіл жаб з файлу Pelophylax_example.sta по генотипам
Другою найважливішою характеристикою досліджуваного матеріалу є стать. Чи можемо ми побудувати відповідний графік тільки для самиць? Для цього треба натиснути кнопку Select Cases (Sel Cond). На рис. 5.1.4 її видно в середині правого ряду кнопок.
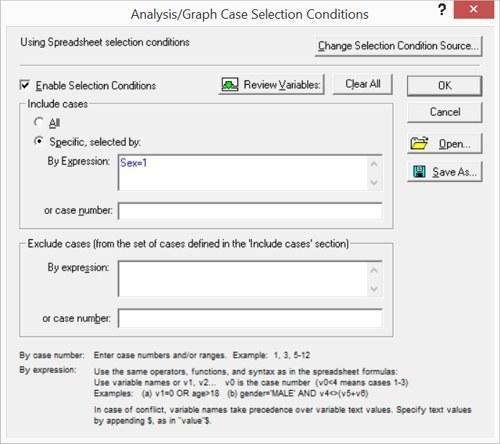
Рис. 5.1.6. Діалог Select Cases (Вибір спостережень)
Відразу після виклику цього вікна переважна частина його органів керування закрита для редагування; щоб їх включити, треба поставити галочку у віконці Enable Selection Condition (Задати умови вибору). Якщо при виконанні якого аналізу користувач не зверне увагу на те, що кнопка «Select Cases» втоплена, він не усвідомить, що він працює не з усією сукупністю своїх даних, а лише з деякою їх частиною. На наступному рисунку показано вікно вибору методу статистичної обробки даних в режимі Basic Statistic and Tables; можна припустити, що після побудови графіків користувач перейшов до власне статистичної обробки. Якщо він не зверне уваги на те, що кнопка «Select Cases» натиснута, може вийти так, що частина наявних у файлі результатів виявиться для нього недоступною. На жаль, це — поширена причина помилок у роботі з Statistica.
Рис. 5.1.7. Увага! Кнопка «Select Cases» натиснута! Якщо це умови вибору, які залишилися невимкненими після попередніх дій з програмою Statistica, частина даних може виявитися недоступною для обробки!
Умови вибору спостережень можна задати кількома різними способами. Можна ввести умови включення спостережень в аналіз (ті рядки, щодо яких ця умова буде виконуватися, будуть аналізуватися, а всі інші — ні). Можна, навпаки, ввести умови виключення спостережень з аналізу. Нарешті, спостереження, що включаються або виключаються з аналізу можуть бути задані простим перерахуванням. При формулюванні умов можна використовувати імена змінних, а можна — їх порядкові номери, допустимо застосування функцій and і or (і, або), а також дужок. Наприклад, умовою «Basin = 2 and v5 = 1 and (v7 = 3 or v7 = 4)» в файлі Pelophylax_example.sta відповідає одна-єдина особина.
Отже, вказавши умова Sex = 1, ми побудуємо гістограму лише для самиць. Крім того, додамо галочку у віконці Breaks between columns (Інтервал між стовпцями) на вкладці Advanced (Додатково), щоб стовпчики не зливалися один з одним.
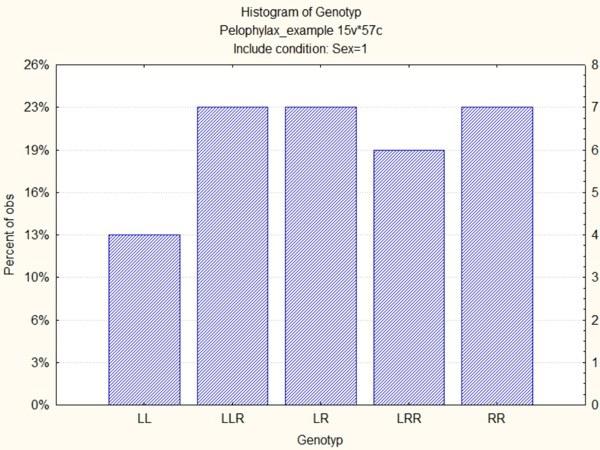
Рис. 5.1.8. На цій гістограмі показані тільки самиці жаб
Щоб побачити розподіл самців, можна побудувати ще одну гістограму, але можна і об'єднати дані про самиць і самців на одному графіку. Для цього необхідно використовувати категоризовать гістограми — Categorized Histograms з меню Categorized Grafs.
Рис. 5.1.9. Categorized Grafs (Категоризовані графіки) є окремою групою в меню Grafs (Графіка)
При виборі змінних в категоризовани гистограммах потрібно вибрати не тільки змінну, різноманітність по якій буде показано стовпцями, а й категорізующую змінну.
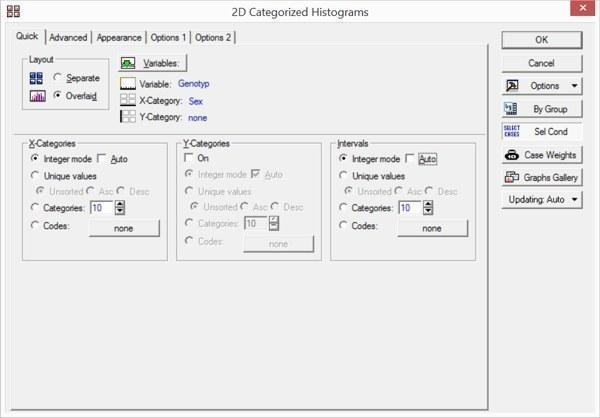
Рис. 5.1.10. Задавання параметрів для категоризованих гістограм. Зверніть увагу на перемикач Layout: Separate або Overlaid (Розміщення: Окремо чи Разом)
При виборі розміщення Overlaid (Разом) відмінності по категорізующей змінної показуються на категоризованих графіках різним оформленням відповідних символів. Можна вибирати дві змінні для категоризації, проте в більшості випадків такі графіки виявляються перевантаженими деталями та інтерпретуються дуже важко.
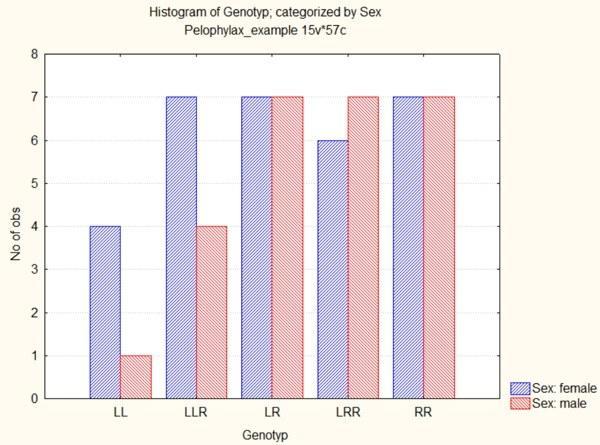
Рис. 5.1.11. Категоризована гістограма: самці і самиці показані окремими стовпцями, які виділені кольором
5.2. Редагування графіка в Statictica
Отримана в попередньому пункті категорізована гістограма дозволяє швидко оцінити обсяг та склад вибірки. Однак цей графік має ряд істотних недоліків.
Наприклад, в колективному несвідомому синій колір асоціюється з чоловічою статтю, а червоний або рожевий — з жіночою (звідси сині ковдри для немовлят-хлопчиків і червоні — для дівчаток). На попередньому графіку самки показані синім, а самці — червоним. Навіть, якщо ми не підтримуємо застарілі гендерні стереотипи, ми можемо стикнутися з тим, що графік буде сприйматися легше, якщо ми змінимо кольори, якими показані статі.
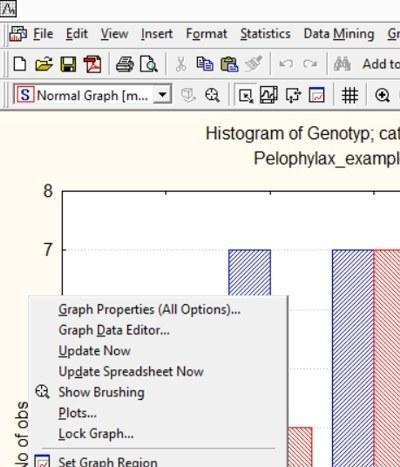
Рис. 5.2.1. Клацання правою кнопкою миші на полі поруч з графіком викликає контекстне меню, одна з опцій якого, Graph Properties (All Options) ... (Параметри графіка ...), дозволяє змінювати його властивості в широких межах
Кольори елементів графіка, як і багато інших його особливостей, можна змінювати за допомогою редактора властивостей графіка. Щоб його викликати, потрібно натиснути правою клавішею миші по полю графіка (за межами власне малюнка) і вибрати Graph Properties (All Options) ...
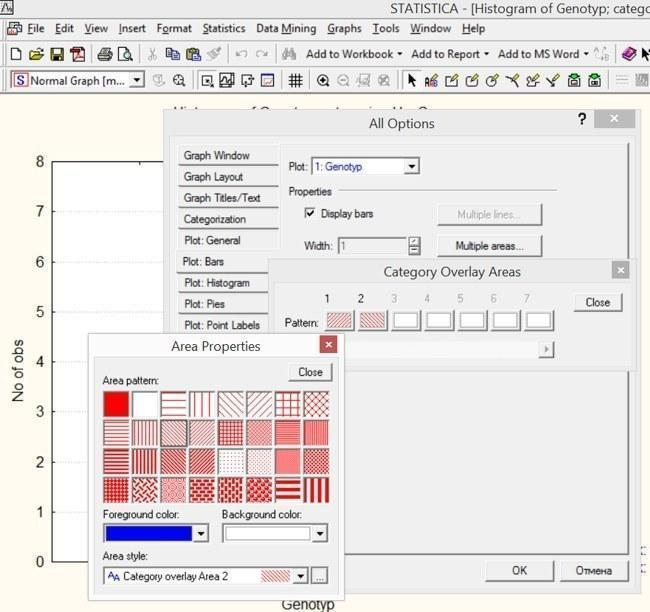
Рис. 5.2.2.У вікні All Options на вкладці Plot: Bars слід натиснути кнопку Multiple areas. З'явиться список стилів стовпців. Клацання по будь-якому з них дозволить змінювати його характер заливки і колір. На малюнку показаний етап, на якому перший стовпець вже зроблений червоним, а для другого колір замінюється на синій...
В цьому режимі є безліч вкладок. У нашому випадку нам треба змінювати властивості стовпців графіка. У відповідному діалозі можна змінювати колір основного візерунка, фону і характер малюнка. У тому випадку, якщо за допомогою обговорюваної програми треба отримати графік, який буде використовуватися при друку чорно-білої ілюстрації, слід прибрати все розмаїття кольорів і передавати особливості різних елементів лише за допомогою різного штрихування, форми, фактури ліній тощо.
У різних версіях програми Statistica розташування кнопок на вкладці All Options є різним. Тим, хто тільки освоює роботу з програмою, можна запропонувати поекспериментувати з різними кнопками і режимами, щоб дізнатися, які функції знаходяться в розпорядженні користувача.
Графіки Statistica мають власний формат і розширення «.stg». Більшість інших програм прочитати цей формат не може. Але більшість програм для Windows може працювати з форматом «.wmf» (Windows metafile). Зберігши графік спочатку в форматі «.stg» (щоб до нього можна було повернутися в будь-який момент і редагувати його засобами Statistica), а потім у форматі «.wmf», можна помістити його в текст Microsoft Word або інших текстових редакторів, а також CorelDraw ! та інших програм для роботи з векторною графікою. Звичайно, в більшості програм Windows існує можливість і простого перенесення графіків і фрагментів таблиць Statistica через буфер обміну.
При збереженні в формат «.wmf» кожен окремий елемент малюнка зберігається окремо. Пунктирні лінії, які на графіках показують рівні, відмічені розміткою шкали, перетворюються в сукупність з безлічі точок або відрізків, які можуть оброблятися відповідними програмами (наприклад, CorelDraw!) дуже довго. Тому іноді має сенс перетворювати пунктирні лінії в безперервні. Для цього досить зробити подвійне клацання мишею на такій лінії, двічі клацнути на кнопці Gridlines ... (Сітка ...) і задати необхідні параметри ліній.
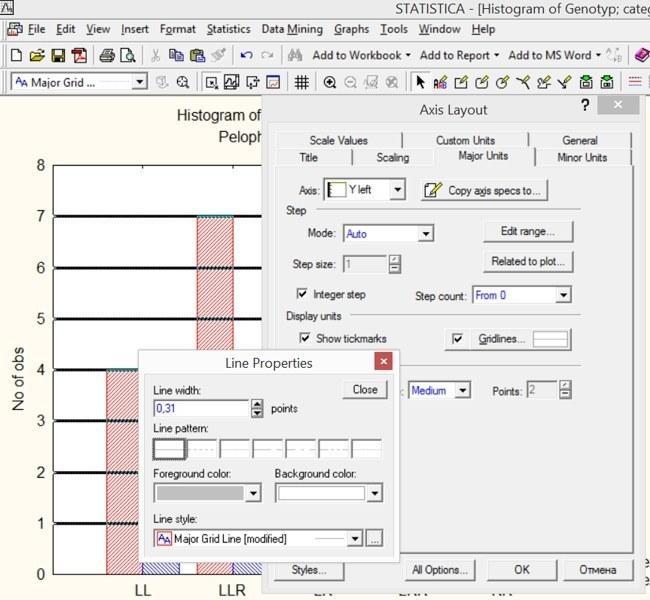
Рис. 5.2.3. Після подвійного клацання на кнопці Gridlines ... (Сітка ...) стали доступними параметри ліній, які за умовчанням відображаються курсивом
Хоча у випадку графіку, що зараз розглядається, гострої необхідності в такій зміні немає, можна змінити діапазон шкал на осях координат та відстань між лініями розмітки. Для зміни проміжку між відмітками на осях можна використовувати вкладки Scaling (Розмітка) або Major Units (Великі відмітки). Щоб редагувати проміжки між лініями розмітки, треба у вікні Mode (Режим) вибрати опцію Manual (Ручний)). Припустимо, ми виберемо тут крок в 3 одиниці.
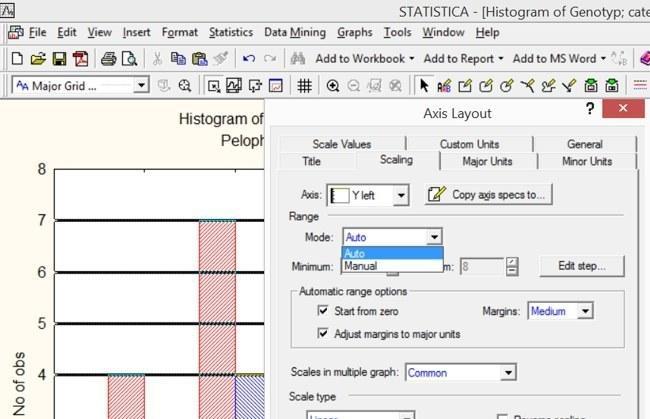
Рис. 5.2.4. Переключивши режим з «Авто» на «Ручний» в цьому вікні можна задати значення для початку та кінця шкали, що відображається на графіку
На вкладці в ручному режимі встановимо мінімум шкали на 0, а максимум — на 9. У вікні Edit step... можна теж перейти в ручний режим і виставити відстань між лініями в 3 одиниці.
Подвійне клацання на позначенні осі, заголовку графіка або легендою (розшифровці позначень) викликає режим редагування цих елементів. Тут можна дати графіку більш адекватну назву. Подвійне клацання на назві осі дозволяє змінити і його.
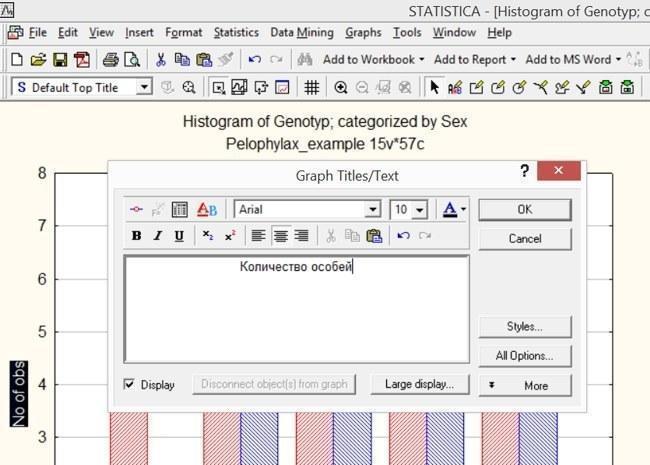
Рис. 5.2.5. Щоб графік добре сприймався, важливо зрозуміло і коректно підписати осі координат
Рис. 5.2.6. Редагування «легенди» (списку умовних позначень графіка)
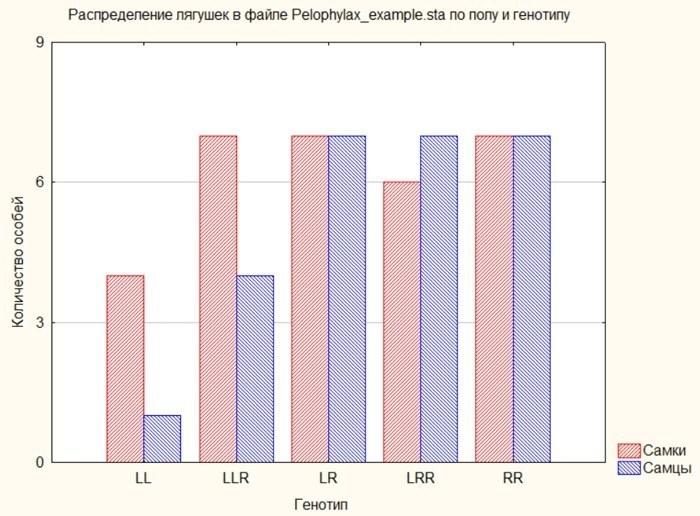
Рис. 5.2.7. Результат переробок графіка, хід яких показаний на попередніх ілюстраціях
5.3. Діаграми розсіювання і лінії регресії в Statictica
Чи не найпотужніший спосіб побудови графіків в Statistica — діаграми розсіювання (Scatterplots). Викликати діалог для їх побудови дуже просто: Graphs / Scatterplots або Graphs / 2D Graphs / Scatterplots. Цілий ряд прийомів роботи з такими графіками вже обговорено в ході опису роботи з гістограмами. Почнемо з простого: побудуємо графік завіcімості ширини голови жаб від їх довжини тіла. Для цього на осі X треба відобразити значення ознаки L, а на осі Y — ознаки Ltc.
Рис. 5.3.1. Побудова графіка залежності ширини голови від довжини тіла
Зверніть увагу: в заголовку графіка буде вказано рівняння регресії, яке описує використаний набір точок.
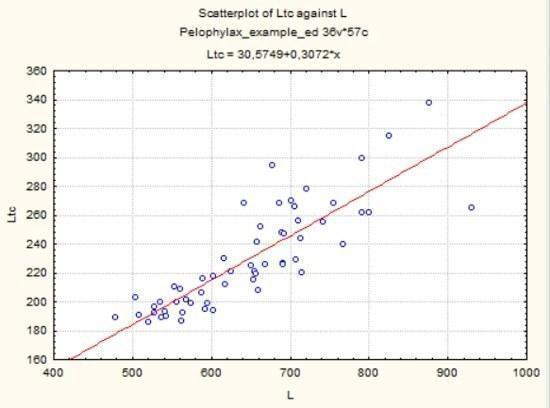
Рис. 5.3.2. Графік, побудований відповідно до умов, що показані на попередньому рисунку
Поняття «регресія» введено Френсісом Гальтоном, творцем біометрії, ще в кінці XIX століття. Функціональна залежність описує однозначний зв'язок однієї величини з іншого; наприклад, вага кулі заданої щільності є функцією її розміру. Регресія описує статистичну залежність. Вага людини залежить від її росту, але крім того — ще від багатьох інших факторів. Залежність росту людини від ваги — не функція, а регресія. Регресія — це залежність середнього значення якоїсь величини від іншої (або інших).
При побудові діаграми розсіювання розглядається певна сукупність точок. Користувач задає характер функції, яка описує зв'язок середніх значень розглянутих величин. Зверніть увагу: на рис. 5.3.1. видно, що в віконці Fit type: Linear (в правій частині діалогового вікна) стоїть «галочка». При побудові діаграми з такими умовами, програма визначає такі коефіцієнти лінійної залежності, які дозволяють найкращим чином апроксимувати наявний набір даних. Апроксимація — це наближення; апроксимувати — приблизно описати; замінити невідому нам залежність (регресію) її найбільш підходящим наближенням.
Як ви можете побачити на рис. 5.3.2, на графіку відображена залежність Ltc = 30,6 + 0,3*L (осі x відповідає змінна L). Ця функція відповідає лінійної залежності: y = a + b * x. На вкладці Advanced можна вибрати й інші функції для апроксимації залежності, яку відбито у взаємному розташуванні точок на графіку.
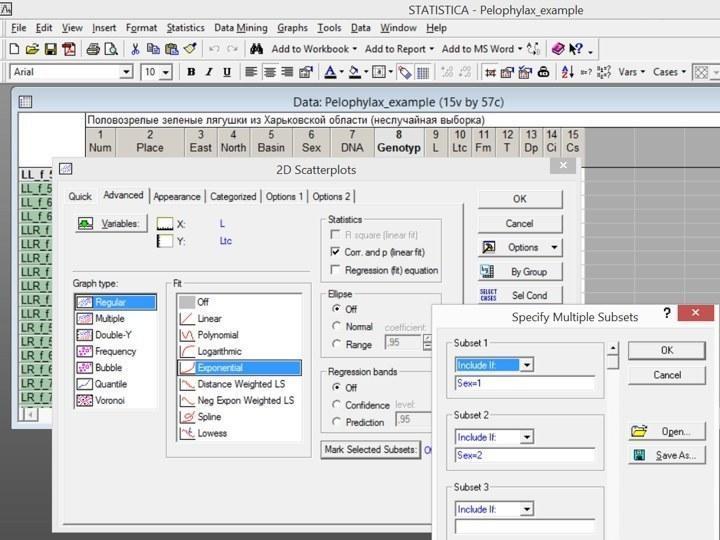
Рис. 5.3.3. Деякі можливості вкладки Advanced діалогу побудови діаграм розсіювання
Зверніть увагу на можливості вкладки Advanced, показані на рис. 5.3.3. Функція підгонки (Fit), обрана для апроксимації залежності між змінними по наявному набору точок, — експоненційна (Exponential), y = a*ex, де e — основа натуральних логарифмів. У вікні Statistics поставлена «галочка» навпроти опції Corr. and p (linear fit) — коефіцієнт кореляції і його рівень статистичної значущості (для лінійної залежності). У вікні Mark Selected Subsets вказані особливі позначення для самиць (Sex = 1) і самців (Sex = 2).
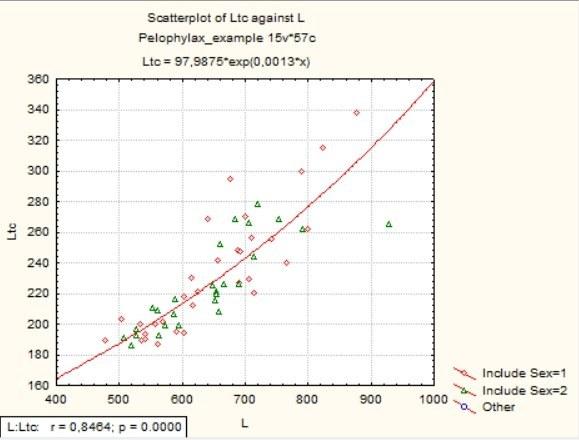
Рис. 5.3.4. Графік, побудований відповідно до умов, що показані на попередньому малюнку
Как видите, во врезке в углу графика появились данные о коэффициенте корреляции Пирсона (r) и уровне его статистической значимости (p).
Сравните результат на рис. 5.3.4. со следующим, построенным с использованием категоризированной диаграммы рассеяния (Graphs / Categorized Graphs / Scatterplots), в режиме Overlaid.
Як бачите, у врізці в кутку графіка з'явилися дані про коефіцієнт кореляції Пірсона (r) і рівень його статистичної значущості (p).
Порівняйте результат на рис. 5.3.4. з наступним, який побудовано з використанням категоризованих діаграми розсіювання (Graphs / Categorized Graphs / Scatterplots), в режимі Overlaid.
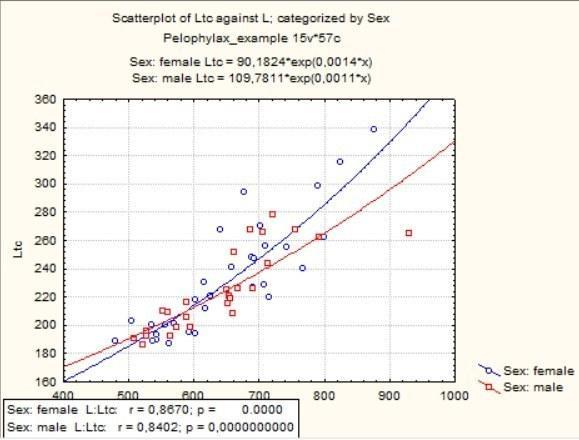
Рис. 5.3.5. Категоризована діаграма розсіювання: дві лінії апроксимації замість однієї
Як ви можете впевнитися, різниця полягає в тому, що в режимі Mark Selected Subsets все обчислення (і лінії регресії, і кореляції) розраховуються для сукупності в цілому, і дві статі лише маркуються різними символами, а в категоризованій діаграмі все обчислення проводяться для обох статей окремо. Який варіант більш підходить до задачі, яку ви розв'язуєте, — вирішувати вам.